Module clean up ideas for the CPAN Pull Request Challenge
At the end of 2014 I signed up for the CPAN Pull Request Challenge; a brilliant idea of Neil Bower’s to clean up CPAN modules in need of a bit of “tender loving care” and to motivate new and not-so-new Perl developers get involved in the maintenance of Perl’s “killer app”.
The idea of the challenge is simple: one is assigned a Perl module each month and in this time must submit at least one pull request to the module’s repository on GitHub. That’s it really, not necessarily a great investment in time and energy for the participant, however cumulatively a huge payback to the community.
As I write this there have been over 290 1 participants sign up for the
challenge! Some are old hands at Perl, who might or might not be using Perl
at work or on a regular basis, and some are complete Perl newbies. It’s
awesome to see newcomers on IRC and the
mailing list who are excited to be
taking part and who are posting messages that they’ve submitted their first
pull request :-)
Things to investigate when cleaning up a module
There are many things to check which can increase the quality of a module/distribution and thus quickly yield a good pull request. Below is a (non-exhaustive) list of things to do and to investigate I’ve come up with while working on my first CPAN distribution of this year: XML::NamespaceSupport. These are effectively notes to myself, however they could be useful to other challenge participants.
Dependencies
When initially familiarising oneself with a new module, it can be helpful to look at the modules upon which a given module depends. Also very helpful is the list of modules which depend upon your module (these are called reverse dependencies).
To find a list of dependencies, go to the MetaCPAN page for your module. On the right hand side, under the maintainer’s/author’s avatar, you will see a heading “Dependencies” with a list of those modules depended upon by your module (if any). For the reverse dependencies, merely click on the “Reverse dependencies” link a little lower in the same column.
Now it’s possible to have a feel for how the module fits into the ecosystem of other modules on CPAN. Things to ask oneself include:
- does the module depend on many modules or only a few?
- do many other modules depend on the module? Or maybe only a couple?
If there aren’t many reverse dependencies, find out who owns the modules depending upon your module. It could be that the module you were given is only used by the author’s own modules (this does happen). If you find yourself in such a situation maybe you should consider asking for a new module. Even if the module you were given lives in a small ecosystem its author is likely to be very appreciative of some help in its maintenance; also, the module might be heavily used by code outside of CPAN, so don’t give up on a module too soon! The effect of updating and cleaning up a module might be much larger than at first sight.
However, if there are several reverse dependencies, this implies that your module is important within the CPAN ecosystem and thus will require extra care in preparing pull requests. Don’t be discouraged though! Even in the “big” modules there are likely to be many places in need of a clean up and even small contributions are worthwhile and appreciated.
Documentation
Clear, concise and well-written documentation can make the life of a module’s users significantly easier and can even determine if the software is used at all. Documentation such as READMEs, and SYNOPSIS and DESCRIPTION sections of a module’s POD are the first port of call for developers and users wanting to make use of the module. Thus, having high quality docs is a worthwhile – if sometimes difficult to reach – goal.
Before even needing to concentrate on the text and its content, there are several things one can do to improve the documentation’s quality.
Use podchecker
Run podchecker over the source code
and any raw POD documentation files. Sometimes POD isn’t formatted
properly, or some tag is missing. podchecker will let you know this and
fixing these errors gives a quality boost to the docs while providing a
simple pull request.
Use a spell checker
Run a spell checker over the source code and documentation files. This can help sniff out any typos which might be lurking. Some spell checkers even understand the programming language, so they know to ignore the code-specific parts of the text and can thus help reduce the number of false positives.
Convert the README to POD or Markdown
GitHub has a feature that a Markdown- or POD-formatted README file in the
base project directory is automatically rendered as HTML on the project’s
front page. This can be a useful change which updates an important part of
the documentation to current standards. One should ask the author first
before doing this, however, just in case such a change isn’t desired.
Check for stale/missing URLs
Check any URLs which appear in the documentation text. Do the web pages still exist? Do they point to the expected location? Have they merely moved? If so, one can update the URL to the current location.
Skim-read the docs
Now to move up a level: the docs also need to be checked for typos (which the spell checker might have missed), textual flow (does the text say what it’s trying to say in a straight forward manner, which is easy to understand and follow?), grammatical errors etc.
Also read the HTML-rendered versions on MetaCPAN or GitHub as well; sometimes one sees things in the non-code versions of docs that weren’t obvious in the code version (and vice-versa).
Read the docs more thoroughly
Also actually read the docs. If they don’t make sense to you, they might not make sense to other people. How could you rewrite them so as to be true to the implementation but be clearer to the code’s purpose? Does the code agree with the documentation (and vice-versa)?
Testing and code coverage
Tests are a Good Thing(TM), and one often sees in TODO lists comments such as “add more tests”, however, how to know what to test? One way to get a good overview of what might need testing is with Devel::Cover.
One can install Devel::Cover via
cpanm like so:
$ cpanm Devel::CoverThe cover command should now be available. It can be used to run the test
suite while collecting coverage information and will generate a report of
the collected coverage information.
For a module using e.g. ExtUtils::MakeMaker (i.e. you have a Makefile
such that you can run commands such as make test to test your module) then
use the following command to find out how much the test suite covers your
code:
$ cover -testor, more explicitly:
$ cover -delete
$ HARNESS_PERL_SWITCHES=-MDevel::Cover make test
$ coverThis will generate an HTML report of code coverage which you can click through to see where any code might require extra tests.
If your module uses Dist::Zilla
then you can use the
Dist::Zilla::App::Command::cover
plugin to run Devel::Cover via the dzil command. First install the
plugin:
$ cpanm Dist::Zilla::App::Command::coverand then run the tests while generating coverage information like so:
$ dzil coverThis will put the coverage output in a directory such as:
/path/to/module/files/.build/random_dir/cover_dbwhich can be somewhat annoying since the build directory is randomly
generated each time dzil cover is run and thus one has to search for the
current coverage.html file each time dzil cover is run. A solution to
this issue is to pass the desired output directory to dzil cover via the
-outputdir option:
$ dzil cover -outputdir $PWD/coverThis will put the coverage report output into the (automatically created if
it doesn’t exist) cover directory within the current directory. Thus one
merely needs to open the coverage.html file in a web browser once and from
then on one only needs to refresh the page after having run dzil cover.
An example coverage report looks like this:
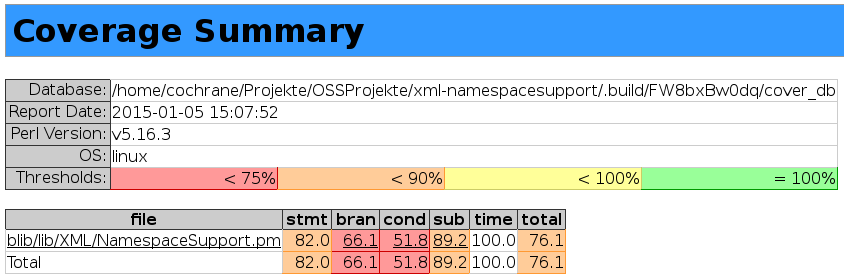
Notice in this report that the subroutine coverage is 89.2% (the value in the “sub” column). This on its own is a good value, however it does imply that some routines aren’t yet tested by the test suite and maybe there are bugs lurking in the untested code. It is thus probably a good idea to try and improve at least the subroutine coverage if nothing else. Also, only roughly half of the conditional paths are being tested, so it could also be worth adding a few tests here in order to push that value up. At the very least more tests would make an improvement to the module while at the same time making reasonably easy-to-create pull request.
Note, however, that code coverage is merely an indicator of test quality. A low coverage percentage (below 60%) indicates that more testing is probably required; a high coverage percentage (95–100%) probably indicates that the main motivator for testing is code coverage and not necessarily test quality. For instance, Martin Fowler expects code coverage in the 80’s or 90’s for well tested code.
Request Tracker tickets and GitHub issues
Since the Pull Request Challenge requires that the CPAN module has a GitHub repository, this means there are probably bug reports in the form of both GitHub issues and Request Tracker (often simply called RT) tickets from CPAN. One can also find a link to open issues on a given module via the “issues” link on the left hand side of the module’s MetaCPAN page.
Have a look at the open issues/tickets and see which ones you might be able to fix (and thus close). Investigating trouble tickets is also a focussed way of looking for things to do when trying to find something worthy of a pull request.
Also think about converting RT tickets into GitHub issues, since RT can be missed by some people and GitHub has more visibility. Make sure to discuss this with the author before doing so to ensure the conversion is actually wanted.
TODO items
Sometimes there is a TODO file as well as RT tickets and GitHub issues. Have a look in this file and see if it can be cleaned up, ideas include:
- remove items referring to completed TODO-items. This is a simple change, and makes an easy pull request (idea from Greg Sabino Mullane).
- consider converting the items in the TODO file into GitHub issues (discuss this with the author first, just in case this isn’t desired).
- completing a TODO item is also a valid pull request
:-). - TODO information is sometimes also mentioned in the README file or even in the module’s POD. Have a look around for more TODO information and aim to concentrate all TODO-related information in one location (preferably as GitHub issues, however the exact location should be discussed with the author).
Nit-picking
Some would call the following points to be nit-picking, and yet others would say that they are basic quality indicators which show that one cares about one’s software. Opinions may differ, however fixing up these small points can make a couple of quick pull requests which do improve the code’s quality in some small way.
Things to check and possibly correct include:
- ensure the GitHub repo is correct in the module’s metadata (idea courtesy of Neil Bowers)
- check the copyright year and update as appropriate
- look for executable files which shouldn’t be (e.g. remove the executable
bit on the file with
chmod -x) - remove trailing whitespace (can be an annoyance for many developers)
- remove automatically generated files from the repository and add an
appropriate entry to
.gitignore. In most cases, automatically generated files don’t need to be included in the repository, since they can be regenerated from the source code files. - add
use strictanduse warningswhere these pragmas are missing. Note that some modules (e.g.Moo,Moose,DancerandDancer2) already have these pragmas enabled. - remove any Subversion tags (e.g.
$Id$). Since the code is now housed in Git, it’s no longer necessary to carry around meta-information from other version control systems. - add and configure a
.gitattributesfile for repositories shared between operating systems that use different line endings. There is documentation on GitHub about how to deal with line endings. This can be a large change, however it allows MacOS X, Linux/Unix work in harmony with Windows systems.
Sundry ideas
Here are some ideas of things appropriate for a pull request which will also lead to an improvement in the module’s overall quality.
Maybe use Moose or Moo for objects
Some modules implement objects from
scratch or use the inside-out object
style. This is
currently not considered to be part of the best practices for development of
object-oriented Perl software and hence developers are encouraged to use
either the Moose object system or its
slimmer counterpart Moo.
Therefore, it might be worthwhile updating one’s module of the month to use
either of these systems (often Moo is preferred, since it is a
trimmed-down version of Moose with the most often required features and
with better performance than its big cousin). This is an issue one would
need to discuss with the module’s author.
Consider converting to Dist::Zilla
Dist::Zilla makes it easier to build, test and release
Perl modules. It contains many plugins which automate the tasks one would
normally have performed by hand when using
ExtUtils::MakeMaker,
Build::Module or
Module::Install.
This can be a fairly major change to a module, its structure and its release
process, so it is definitely a good idea to discuss such a change with the
module’s author before submitting this as a pull request. Nevertheless, due
to Dist::Zilla’s power, it can be a worthwhile change and can help to
become acquainted with a build and release system which is becoming widely
used in the Perl community.
Check the dist’s minimum Perl version
Perl::MinimumVersion; perlver .
Check for issues with Perl::Critic
Perl::Critic with its associated
command line program perlcritic can be very useful in finding standards
or best-practice-related issues in Perl code. However, Perl::Critic can
be very pedantic and should thus be used with caution. Nevertheless, this
is a good, automated way to check for potential bugs in a module’s code, and
removing bugs (even potential ones) is a great way to give back to the
community and create your minimum pull request for the month.
Check the module’s kwalitee
It’s very difficult to measure the quality of a module, hence the quantity kwalitee was created which measures in an inexact manner a module’s quality. This is measured by the CPAN Testers for all modules on CPAN (see also their description of kwalitee indicators).
How does one measure kwalitee for a module one is working on? The quick
answer is the Test::Kwalitee
module.
If necessary, install the module via cpanm:
$ cpanm Test::KwaliteeBuild the distribution so that it can be checked:
$ make dist # ExtUtils::MakeMaker
# or
$ dzil build # Dist::ZillaNow enter the directory containing the built distribution and create a test
file in its test directory (e.g. t/99_kwalitee.t) with the following
content:
use strict;
use warnings;
use Test::More;
BEGIN {
plan skip_all => 'these tests are for release candidate testing'
unless $ENV{RELEASE_TESTING};
}
use Test::Kwalitee 'kwalitee_ok';
kwalitee_ok();
done_testing;Now simply run the test suite with the standard prove command (make sure
to set the RELEASE_TESTING environment variable):
$ RELEASE_TESTING=1 prove -lr tIf you are greeted with errors or warnings generated by Test::Kwalitee
then these are things to tidy up and submit as a pull request.
Check the wording of error messages
Error and warning messages are how a module tries to communicate with a user to let them know that there is a problem, where the problem is, and possibly how to correct it. Thus such messages should be as clear and concise as possible. Check the error and warning messages for simple things like typos, textual flow problems or grammatical errors etc. Also try to think of how they might be made clearer so that a user doesn’t need to read the source code in order to find out what is really going wrong and thus how to fix the issue they’ve come across.
In some rare cases other code could explicitly depend upon a certain string appearing in an error message, thus it is a good idea to discuss changes to error messages with the module’s author before investing too much time here.
Build and test the module on Travis-CI
Travis-CI is a free (for open source projects) continuous integration service where one can build and test software under various programming environments. For example, it is possible to build and test Perl modules under several different Perl versions (currently from version 5.10 to 5.20). One can set up Tracis-CI to watch GitHub repositories, and if new code is pushed to the repository then a script checks out the repo and builds and tests the software.
In order that Travis-CI can build and test the software correctly, a
YAML-formatted file called
.travis.yml is required in the repository’s base directory. For a Perl
module using Dist::Zilla as a build system, the .travis.yml file looks
something like this:
language: perl
perl:
- "5.26"
- "5.24"
- "5.22"
- "5.20"
- "5.18"
- "5.16"
- "5.14"
- "5.12"
- "5.10"
install:
- cpanm Dist::Zilla
- dzil authordeps --missing | cpanm -n
- dzil listdeps --missing | cpanm -n
script:
- dzil test --author --releaseThe language directive specifies which programming language/environment to
set up (in our case Perl). One then specifies the list of Perl versions to
use to test our module via the perl directive (since it is possible that
the module works under some versions of Perl, but not under others).
The install directive contains a list of commands used to install the
prerequisite software necessary for our module to run successfully. In the
case shown here, we make use of Dist::Zilla’s dependency-finding
functionality to list the required Perl modules and pipe this output to
cpanm in order to install them.
The script directive then contains a list of commands used to run the test
suite. Here we run the tests from Dist::Zilla, specifying that the
author- and release-related tests should also be run.
Now, as soon as new code is pushed to the GitHub repository, Travis-CI will create a virtual machine for each Perl version, install any necessary prerequisite software, build the Perl module and run its test suite within that virtual machine, informing us at the end if any problems occurred (the virtual machine is automatically destroyed after its scripts have been run).
Thus, adding a .travis.yml file to a module – and getting it to the point
that Travis-CI runs correctly – is a good addition to a project and a
worthy pull request.
Ideas from other sources
After having spent a while writing this post, I found that Gabor Szabo has already collected a list of articles covering topics mentioned here as well as other examples of things to do to improve the overall quality of Perl modules.
Closing thoughts
If you got this far, thanks for reading!
Remember, even if it seems that with some modules there aren’t many issues to address, there is still much that can be done. Simply bringing a module up to scratch with modern Perl coding standards is a gain for the entire community.
Good luck with the rest of the Pull Request Challenge!
-
Update: as of 19th of January, there are now 360 participants! ↩
Support
If you liked this post and want to see more like this, please buy me a coffee!